AI’s Human Bottleneck
Silicon Valley is writing some mighty big checks these days, both literally and figuratively. If what AI labs say is true, we’ll soon be sipping piña coladas on the beach as autonomous agents cure our cancer, run our companies, and wipe our asses.
I made that last one up, but we both know there’s a VC-backed startup somewhere pitching “elder care hygiene” as the next trillion-dollar AI market.
The future will be incredible! All that stands in our way are the three horsemen of the AI apocalypse: power, chips, and data. Oh, and maybe a few minor details around the whole social upheaval, global war, and human extinction stuff.
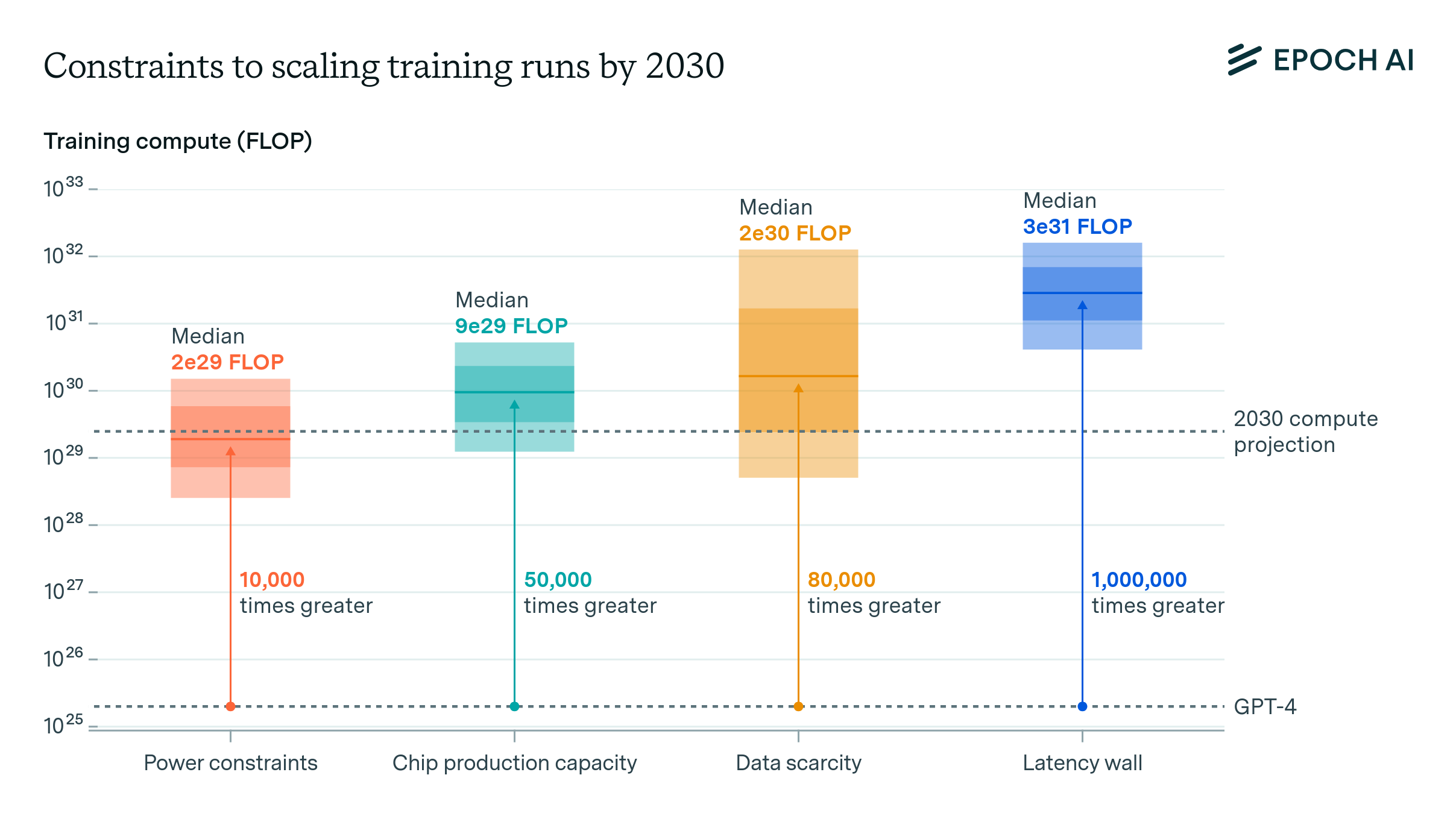
Commonly cited AI bottlenecks (source: Epoch AI)
You can probably tell that I’m skeptical. It’s not that I doubt AI’s economic potential. Trillion-dollar valuations might seem absurd — until you do the math.
I’ve spent $5,938.81 with OpenAI over the past 12 months. That includes my ChatGPT Pro subscription and API fees for Purpose Fund and Paper-to-Podcast. That’s a lot of money, but the value I derive from OpenAI’s products is substantially more.
OpenAI claims to have 800 million weekly active users. If the average user spent as much as I do, that would equate to around $5 trillion in annual revenue. Oh, and that doesn’t even include the $3,000 I’ve dropped on other AI platforms.
For reference, the world’s largest company by revenue today is Walmart, which generates $700 billion. The potential market for AI is absolutely staggering.
Even so, I’m confident we’re in the middle of an AI bubble, which puts me in the uncomfortable company of skeptics who insist AI is just overhyped autocomplete. Respectfully, those people are full of shit.
If anything, AI is underhyped. The problem is that the path to prosperity runs through a perniciously persistent bottleneck: humans.
Bottleneck #1: Prompting
I have accounts with multiple AI companies: OpenAI, Anthropic, Google, Replit, and ElevenLabs. Do you know what their models are doing for me right now? Absolutely nothing.
As I write this article, my AI interns sit idle. I have thousands of GPUs at my disposal, but nothing happens unless I ask.
That’s not entirely true, but it is to a first approximation. Last night, OpenAI ran my weekly survival problem report and curated a “Today’s pulse” that I probably won’t read. However, those activities used a few thousand tokens at most.
I’ll use tokens as a proxy for AI work. If you’re new to AI and don’t understand how large language models work, check out this primer from the Financial Times. It’s the best I’ve found.
For comparison, I used 312,617,297 tokens during the first week of October. That’s roughly 400 times more than you’ll find in War and Peace. What was I doing with all those tokens? I was rebalancing my portfolio, scoring every S&P 500 company across nine social impact priorities.

My OpenAI API usage in October 2025
To burn through tokens that quickly, I had to come up with an idea, write thousands of lines of code, and feed OpenAI cash until the results matched what I wanted. You don’t consume a billion tokens a year by accident.
OpenAI recently recognized my former employer, McKinsey, for passing the 100 billion token mark. That’s a huge milestone, but McKinsey has about 40,000 employees. That works out to 2.5 million tokens per person, which is less than one percent of what I used last month.
Despite my ridiculous token consumption, prompting is still a bottleneck. I can’t ask questions, assign work, and process responses quickly enough to keep the AI interns busy. Also, if we’re being honest, I usually forget to ask them for help.
How do we get to a world where AI works around the clock instead of waiting for us to tell it what to do? The prompting bottleneck won’t fall because of a single breakthrough. It’ll fall as new features, applications, and devices roll out over the next few years:
Speech modality: AI voice modes are clunky today, but don’t be surprised to find yourself talking to AI more in the future. Most people speak two or three times faster than they type.
Ambient AI: One solution to the prompting bottleneck is to have AI always listening. If that sounds creepy, you may want to avoid doctors, call centers, and work meetings.
Reasoning models: Remember when ChatGPT would blurt out the first response that came to mind? Now, AI models can work uninterrupted for 20 minutes or more. Longer task durations mean less frequent prompting.
Context engineering: Much of what we include in prompts is context (e.g., instructions, documents). As models tap into our data and learn how we work, we’ll be able to prompt them even faster.
Multi-agent architectures: The reason I consumed 300 million tokens in a week is that I used AI to prompt AI. You don’t have to worry about the prompting bottleneck when you take humans out of the loop.
New devices: OpenAI didn’t spend $6.4 billion on Jony Ive’s company because they love beautiful hardware; they did it because prompting AI with mobile phones and computers sucks. There must be a better way.

AI task duration is increasing rapidly (source: METR)
AI companies need to supercharge token consumption to justify their eye-watering infrastructure investments. The math doesn’t work at current demand levels. Data centers coming online in 2026 could process nearly 5 million tokens per year for every person on Earth, double the rate at which McKinsey consultants consume tokens today.
I made some BIG assumptions in calculating the 5 million tokens/year number. These numbers aren’t readily available. Here’s my rough math:
Analysts expect about $500 billion in AI infrastructure spending in 2026
If 40 percent goes toward GPUs, that’s $200 billion earmarked for compute
At $25,000 per GPU, that level of spending buys around 8 million GPUs
Assuming each GPU delivers 300 tokens each second (conservative), that adds up to 7.6×10¹⁶ tokens per year if the GPUs run flat out
Systems never hit perfect utilization. At a 50 percent utilization rate, the effective capacity drops to about 3.7×10¹⁶ tokens per year
Spread across 8 billion people, that’s 4.7 million tokens per human per year
That might sound daunting, but don’t underestimate Silicon Valley’s ability to spur demand. They did it with social media, and they’ll do it again with AI. We won’t always love their methods, but that won’t stop us from embracing their products and services with open arms.
Prompting won’t hold AI back for long.
Outlook: Prompting will constrain AI for another 2–3 years, but token use should skyrocket as new features, applications, and devices come online. Prepare for a world where AI is always on, always available, and always listening.
Bottleneck #2: Trust
AI models are blowing through traditional benchmarks (e.g., MMLU, SWE-Bench) so fast that researchers are having to invent new ones. The models aren’t perfect, but each new generation is more capable than the last. You’d think that would translate into us trusting models more over time.
Yet, the data tells a different story. A KPMG survey found that trust in AI systems declined from 2022 to 2024. The models got better, but our trust in them eroded. What’s happening?

Trust in AI is eroding, not increasing (source: KPMG)
AI systems are messy. Their probabilistic nature makes them difficult to predict — and difficult to trust. To illustrate my point, let’s talk about a deterministic technology: the calculator.
If you type “6472 × 31” into a calculator, you won’t feel an overwhelming urge to double-check the result. You’ll accept “200,632” and move on with life. That trust extends beyond individual calculators. If I hand you mine, you’ll trust it too.
Now, imagine my calculator gave you an answer of “21.” You’d stop trusting my calculator immediately, but you’d probably still trust calculators. Mine violated your trust, but it did so in an obvious way.
What if mine answered “200,634”? Crap, now we have a problem. That answer is believable… and wrong. Suddenly, you’re not just doubting my calculator; you’re doubting all calculators. You might even start second-guessing your own.
Probabilistic technologies work perfectly right up until the point when they don’t. Worse, their mistakes aren’t always easy to spot. AI hallucinations terrify us because they can be lurking anywhere. What good is an AI to us if we constantly have to check its work?
It’s worth lingering on this point for a moment. Lower hallucination rates don’t necessarily make models easier to trust. In fact, it can make them more difficult to trust because errors are less noticeable.
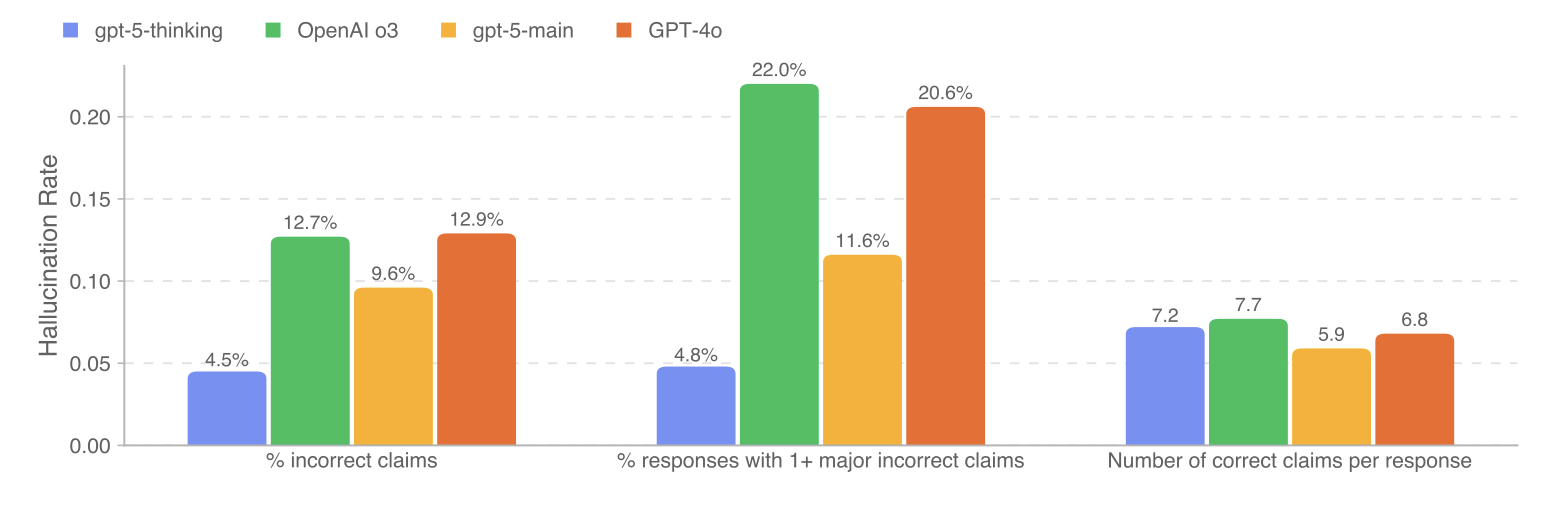
Factuality on ChatGPT Production Traffic (source: GPT-5 System Card)
Fortunately, the behavior I’m describing isn’t unique to AI. It’s a bug we’ve tolerated for over a million years in another probabilistic calculator: the human brain. The difference is that we’ve evolved methods for trusting other humans. We don’t yet have the same for AI.
Except we do; they’re the same. We place our trust in humans at two levels: individuals and groups. Let’s begin with individuals.
How many people do you trust? I don’t mean acquaintances. I’m talking about people you’d trust with your family, secrets, and livelihood. Five people? Maybe ten? It can take years to suss out whether a person is trustworthy.
Unfortunately, AI is a moving target. Companies are releasing new models at a rapid clip. Individual models don’t have time to earn our trust before the next generation arrives. It’s like trying to trust a coworker whose capabilities and personality change every few months.
When trust in individuals isn’t possible, we look to groups. We don’t need to trust every person in our neighborhoods, companies, or countries. We just need to trust the policies, standards, incentives, processes, safeguards, and norms governing those groups.
In the context of AI, that means trusting the companies behind the models and applications. Google released Gemini 3 this week. Whether I trust it has little to do with the model itself; Gemini 2.5 was already pretty good. It depends on how much I trust Google.
We won’t all trust the same AI companies. I trust OpenAI more than xAI, Anthropic more than DeepSeek, and just about every company more than Meta. If my political views, country of origin, or social media habits were different, I’d probably trust other companies. AI isn’t a winner-take-all market.
Evidence of the trust bottleneck won’t be obvious, but there will be plenty of signs if you look:
Redundant controls: Insistence on costly checks, audits, and human-in-the-loop steps even when the probability and/or risk of failure is low.
Double standards: Higher quality requirements for AI-powered systems than human-powered ones. We already see this with self-driving cars.
Data starvation: Unease with giving AI models access to all the data they need to do their job effectively due to privacy concerns.
Delayed adoption: Unwillingness to adopt new models and capabilities, even after they’re proven safe and reliable by experts.
I don’t trust any AI company with my family, secrets, or livelihood today. An always-on, always-available, always-listening AI in my home feels like a dystopian nightmare, not a utopian dream. I’ll get there eventually, but I need time.
Warren Buffett once said, “It takes 20 years to build a reputation and five minutes to ruin it.” It won’t take decades for AI companies to earn our trust, but it’ll take longer than most people think.
AI still feels like a novelty because the prompting bottleneck keeps its reach contained. We haven’t yet had to confront what it means for AI to permeate every corner of our lives. Trust is a luxury for now, not a necessity. That’ll change soon enough.
Outlook: People will learn to trust AI companies at their own pace. Expect a 5–10 year lag between new capabilities and mass adoption. The prompting bottleneck is obscuring how much trust will matter.
Bottleneck #3: Expertise
Remember when AI couldn’t do basic math? Shitposters had a field day sharing examples of multi-billion parameter models struggling to solve elementary math problems.
2023 was a simpler time.

Posts like this won’t age well
Fast forward a couple of years, and models are taking home gold medals at the International Math Olympiad. They still make mistakes, but betting against AI capabilities is a fool’s errand.
There’s just one small problem: Most of us lack the expertise to push the latest AI models. The last time I did a math proof, Netscape was a thing. Google’s protein-folding AI algorithm is as useful to me as a chocolate teapot. Each leap forward leaves me a little further behind.
ChatGPT has a penchant for phrases like “chocolate teapot” and “Swiss Army Knife.” For a while, I avoided those and other supposed tells like emdashes. Eventually, I just went back to writing how I wanted. Self-censoring to dodge accusations of using AI is exhausting. If you’re the kind of person who enjoys hunting for gotchas, maybe it’s time to find a new hobby.
Researchers seem to have lost sight of what “average intelligence” really means. The Center for AI Safety recently published a paper claiming OpenAI’s latest model, GPT-5, scored a 57% on its artificial general intelligence (AGI) test. The test aims to show how close AI models are to human-level intelligence.
That score sounded low, so I dug into the research.

Sample questions from General Knowledge section of the AGI test (source: A Definition of AGI)
The authors claimed their questions represented “knowledge that is familiar to most well-educated people or is important enough that most adults have been exposed to it.” Really? Are you sure? I don’t consider questions like these general knowledge:
State the molecular geometry for the sulfur tetrafluoride molecule
Describe the role of the Guardian Council in Iran
What were the main goals of the Congress of Vienna in 1815?
Have these researchers met actual people? What’s the point of an AGI benchmark that wouldn’t categorize the average human as AGI? I’m not winning any Nobel Prizes, but I should be able to pass an AGI test with flying colors.
I’m not ranting for the sake of ranting — ok, maybe a little. I’m ranting because benchmarks like this obscure a real bottleneck: expertise. What good are super-powerful AI models if most of us don’t have the necessary expertise to use them?
Imagine OpenAI upgraded your ChatGPT subscription to “God tier” while you’re sleeping tonight. The new model can perform any task with perfect accuracy. Would you notice? How would you test it?
Perhaps you ask it to cure cancer. The model churns for a few hours and returns with a 1,500-page report. The research looks legit, but you can’t even pronounce half the words in it. Did you move society forward, or did you just burn a few million tokens for fun?
Fewer than 2% of people worldwide have a PhD, and most of us work in jobs requiring more common sense than uncommon insight. Our intelligence tends to be broad, shallow, and redundant. An AI-powered economy requires intelligence that’s narrow, deep, and unique.
Can we learn new skills? Of course, but it takes time. We like to think we can reinvent ourselves at any age, but the kind of deep expertise we’re talking about usually accumulates over generations, not within them.
Growing up outside Detroit, many of my family members worked in the auto industry. I saw firsthand that the prospects for a high-paying factory job without a college degree were fading fast. I didn’t go to college to chase opportunity; I went to avoid disruption.
As it stands, there are only a few ways around the expertise bottleneck:
Education: Revamp how we learn, creating paths for each of us to build deep expertise in unique, dynamic fields throughout our lives.
Amplification: Give the experts we already have access to billions of AI workers to scale the impact of their expertise.
Integration: Connect AIs directly into the physical world so they can learn and experiment alongside us.
We’ll probably employ some combination of all three. The problem is that all of this takes time. We’re talking decades, possibly generations. And during that span, the gap between what’s technically possible and what’s realistically feasible will only grow.
Outlook: After we get past the prompting and trust bottlenecks, we can look forward to a 10+ year period where AI’s impact depends on the number of people skilled enough to use it.
The Moonshot
The economically useful life of an AI chip (GPU, TPU) is about three to five years. That might be enough time to overcome the prompting bottleneck and maybe even the trust bottleneck. It’s not nearly long enough to clear the expertise bottleneck.
That’s why AI labs are banking on AGI. It’s the only plausible way around the expertise bottleneck before the current generation of chips becomes obsolete. The banks, sovereign wealth funds, royal families, and eccentric billionaires aren’t pouring trillions of dollars into data centers just to power AI-slop machines.
Here’s the rub: I estimate AGI is probably a decade away. I won’t rehash the details since I’ve already written a five-part essay on it, but the TL;DR is that AI labs still don’t have a reliable benchmark for the human brain. They can forecast the tech curve, but they have little idea what target they’re trying to hit.

My “please don’t treat this as science” projection for AGI (Source: Neuroscience Rewired)
It’s difficult to say whether we’re in an AI bubble because it’s not something you can forecast. It’s more of a coin flip. If labs create AGI by 2030, the human bottlenecks barely matter. If they don’t, we’re likely in for another AI winter.
The upside is that the next AI winter shouldn’t last long. Once the dust settles, we’ll see that the infrastructure we’ve built is incredibly valuable. If we can overcome the human bottlenecks, the resulting growth will likely bankroll our final push to AGI.
Once that happens, maybe we’ll finally get those piña coladas and ass-wiping robots Silicon Valley promised.
A guy can dream, can’t he?

Source: ChatGPT